A Simple Class Diagram
Our example is going to be very straightforward. We have some basic details about a person plus a set of his friends:

When we map this to a traditional physical RDBMS, things begin to change.
The Equivalent Relational Model
In Oracle, if I wanted to use object-relational features, I could create an array of VARCHAR to store the friends. Different databases have different ways of implementing this, but here I’m taking the lowest common denominator approach and will break-out the friends array into a separate table.
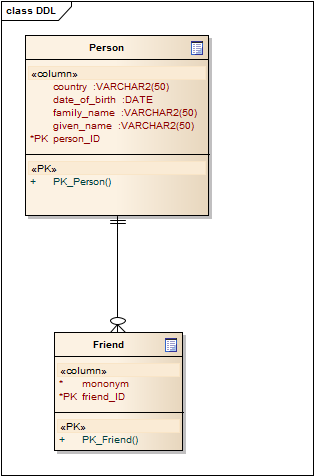
I’ve used mononym because it’s is a one-word name by which a person is known. This is a classic example of transforming an object model to a physical RDBMS model. The point is, designing relational databases it’s a well-defined and generally quite well known.
The Equivalent Cassandra Model
But that’s not so much the case with NoSQL databases. Things get a lot weirder when creating a physical data model for Cassandra, especially if you come from a relational database background.
Modelling Principles
Data modelling in Cassandra uses a query-driven approach, in which specific queries are the key to organizing the data. So, before you can do any Cassandra specific modelling, you have to know your queries. And if your queries change, you can pretty much assume that your database schema will have to change too.
On top of that you need understand the access path of each query to organize data efficiently. There are, broadly speaking, three access paths: 1) partition per query, 2) partition+ per query, and 3) table or table+ per query.
The first one is the most efficient; a query retrieves all rows from just a single partition. The second and third paths refer to retrieving data from a few partitions in a table or from many partitions in one or more tables, respectively. While these access paths may be unavoidable in some cases, you should try to steer away from them as much as possible to achieve best query performance.
Tables, Primary Keys, and Queries
Cassandra’s data model is a partitioned row store. Rows are organized into tables. Tables have primary keys and columns. It sounds a bit RDBMS-like, but it starts to differ. The first part of a primary key is the partition key. Then, within a partition, rows are clustered by the remaining columns of the primary key.
Cassandra data modelling focuses on the queries, and queries are best designed to access a single table. It follows that all entities involved in a relationship that a query uses must be in the same table. Some tables will involve a single entity and its attributes. But others will involve more than one entity and their attributes. Including all data in a single Cassandra table is a bit like creating a materialized view in a relational database. For the same reason that a query against a materialized view runs faster, Cassandra uses this single-table single-query approach to run queries faster.
In Cassandra, queries are optimized by primary key definition. To a large extent, it’s the design of the primary key that supports the WHERE clause of a query. Because Cassandra is by design a distributed database, efficiency is gained when data is grouped tightly together on nodes by partition. This grouping is defined by the primary key.
Our Conceptual Model
The Person entity as given_name, family_name, country, and data_of_birth as attributes, along with a set of friends:
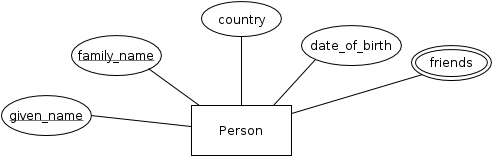
We’re going to look at three queries that our application needs to execute along with the table and primary key design that supports each one.
Our Queries and Tables
The example only has one entity so our CQL will have no joins but then again CQL will never have joins because Cassandra does not support them.
SELECT country, family_name, friends FROM persons_by_given_name WHERE given_name = ? and date_of_birth = ?;
The table that supports this query has all the attributes and a primary key to support the where clause:
CREATE TABLE persons_by_given_name ( given_name TEXT, date_of_birth TIMESTAMP, country TEXT, family_name TEXT, friends SET<TEXT>, PRIMARY KEY ((given_name, date_of_birth)) ) ;
The second query is the same with the exception that date_of_birth is selected by range (rather than by equality).
SELECT country, family_name, friends FROM persons_by_given_name_dob WHERE given_name = ? and date_of_birth > ?;
So the supporting table is the same with the exception of the primary key definition:
CREATE TABLE persons_by_given_name_dob ( given_name TEXT, date_of_birth TIMESTAMP, country TEXT, family_name TEXT, friends SET<TEXT>, PRIMARY KEY ((given_name, date_of_birth)) WITH CLUSTERING ORDER BY (date_of_birth ASC) ) ;
The last query makes date_of_birth more prominent:
SELECT given_name, family_name, friends FROM persons_by_dob WHERE date_of_birth = ? and country = ?;
So the supporting table moves date_of_birth to the high order end of the primary key:
CREATE TABLE persons_by_dob ( date_of_birth TIMESTAMP, country TEXT, given_name TEXT, family_name TEXT, friends SET<TEXT>, PRIMARY KEY ((date_of_birth, country), given_name)) WITH CLUSTERING ORDER BY (given_name ASC) ) ;
If this looks like a really tedious exercise, you’re not far wrong. Furthermore, until Cassandra 3.0, these additional tables had to be updated manually by the client application. Since Cassandra 3.0, however, these additional tables can be defined as materialized views that automatically receive updates from their source tables.
Conclusion
Data modelling has always been a cornerstone of databases. Conceptual data modelling and relational database design have been extensively studied and are generally well understood. Unfortunately, the majority of relational data modelling techniques are not transferrable to NoSQL databases.
NoSQL modelling remains a challenging and open problem. But you can start by knowing your use cases and focus your design to support them, including data replication for your most frequently used queries, you’ll be off to a good start.